JSON Server - testowe REST API w kilka minut
2017-01-16 · node-js · tools · testowanie
Czasami chciałbyś od razu rozpocząć pracę na frontendzie aplikacji, ale okazuje się, że musisz czekać, aż zespół dopowiedziany za backend wystawi działające API.
Podobnie sprawa się ma z prototypowaniem. Chcesz zrobić coś szybko, ocenić nową koncepcję, stworzyć tutorial, czy poszukać odpowiedzi na pytanie lub sprawdzić który kształt odpowiedzi z serwera najlepiej pasuje. Potrzebujesz więc na tyle dobrego, pełnego prototypu, aby uzyskać wiarygodny osąd, czyli potrzebujesz backendu, CRUDów - JSONowej odpowiedzi z serwera, a przecież nie chcesz tracić dużo czasu na tworzenie prawdziwego web serwisu.
Może również się okazać, że API istniejące w twoim środowisku dev lub QA jest powolne, lub wadliwe, a potrzebujesz szybkich, spójnych i wiarygodnych odpowiedzi z serwera.
Podobnie, jeżeli musisz pracować offline, a chcesz mieć pod ręką działające API.
Odpowiedzią na te problemy jest JSON Server. Jest to bardzo przydatny opensourcowy moduł npm, chodzący na serwerze Express, który pozwala łatwo zamodelować backend. Przy minimalnej konfiguracji, w kilka minut otrzymujesz Web API, Web serwis, JSON API i RESTfull API na potrzeby dewelopmentu lub testowania.
Wymagania
- Node.js: środowisko uruchomieniowe
- npm: manager pakietów dla Node.js
- dowolne narzędzie do wysyłania zapytań na serwer:
- cURL - w przypadku instalacji pod Windowsem, pomocna może się okazać odpowiedź na Stack Overflow
- Postman
- Chrome - od wersji 42 fetch() jest w pełni wspierany przez Chrome
Instalacja
Aby zainstalować JSON Server, otwórz konsolę i wpisz poniższe polecenie:
npm install -g json-serverFlaga -g spowoduje, że serwer zostanie zainstalowany globalnie w systemie, co pozwoli uruchomić go z każdego miejsca.
Uruchamianie
Aby uruchomić JSON Server, otwórz wiersz poleceń i wpisz jedno z poniższych poleceń (w zależności od tego, co jest źródłem danych):
json-server db.jsonW tym przypadku źródłem danych jest plik db.json znajdujący się na dysku, np.:
{
"posts": [
{ "id": 1, "title": "json-server", "author": "typicode" },
{ "id": 2, "title": "jsonplaceholder", "author": "also typicode" }
],
"comments": [
{ "id": 1, "body": "some comment", "postId": 1 }
],
"profile": { "name": "typicode" }
}json-server http://jsonplaceholder.typicode.com/dbW kolejnym przypadku źródłem danych jest onlinowe REST API - JSONPlaceholder.
json-server db.jsW ostatnim przypadku źródłem danych jest skrypt JavaScriptowy; korzystając z pliku JS zamiast JSON, można utworzyć dane programowo:
function generatePosts () {
var posts = []
for (var id = 1; id <= 50; id++) {
var title = 'Post ' + id;
var author = 'John Doe';
posts.push({
"id": id,
"title": title,
"author": author
})
}
return { "posts": posts }
}JSON Server można również osadzić we własnym skrypcie JavaScriptowym:
var jsonServer = require('json-server');
var server = jsonServer.create();
var router = jsonServer.router('db.json');
server.use(jsonServer.defaults);
server.use(router);
server.listen(3000);Routing
Domyślnie serwer zapewnia najpotrzebniejsze routingi. Zakładając, że uruchomiliśmy serwer, którego źródłem danych jest plik db.json, to w przypadku posts (plural routes) będą to:
GET /postsGET /posts/1POST /postsPUT /posts/1PATCH /posts/1DELETE /posts/1
natomiast dla profile (singular routes) mamy:
GET /profilePOST /profilePUT /profilePATCH /profile
Można również dodać inne routingi. W tym celu należy stworzyć plik routes.json, np.:
{
"/api/": "/",
"/blog/:resource/:id/show": "/:resource/:id",
"/blog/:title": "/posts?title=:title"
}Następnie uruchamiamy serwer, używając opcji --routes lub -r:
json-server db.json --routes routes.jsonW wyniku tego otrzymujemy dodatkowe routingi:
/api/postsodpowiadający/posts/api/posts/1odpowiadający/posts/1/blog/posts/1/showodpowiadający/posts/1/blog/jsonplaceholderodpowiadający/posts?title=jsonplaceholder
Właściwości
Żądania POST, PUT, PATCH i DELETE wykonywane na bazie, której źródłem jest plik json z dysku, modyfikują również zawartości tego pliku źródłowego; w przypadku innych źródeł, operacje działają na kopii schematu.
Poza wspomnianymi żądaniami JSON Server wspiera również GET i OPTIONS.
Wartości identyfikatora (id) nie są zmienne. Każda wartość id w body żądania PUT lub PATCH będzie ignorowana. Tylko wartość ustawiona w żądaniu POST będzie respektowana, o ile nie jest już zajęta.
POST, PUT lub PATCH powinien zawierać nagłówek Content-Type: application/json, aby można było używać JSONa w body żądania. W przeciwnym przypadku w odpowiedzi otrzymamy 200 OK, ale bez wprowadzania zmian do danych.
Można uzyskać dostęp do API z dowolnego miejsca za pomocą CORS i JSONP.
Domyślnie serwer uruchamia się na porcie 3000 localhosta: http://localhost:3000.
Wiele domyślnych ustawień, np. delay (dodaje opóźnienie odpowiedzi serwera), host, port, można nadpisać, tworząc własny plik konfiguracyjny json-server.json, np.:
{
"port": 3001,
"delay": 2000
}a następnie uruchomiając, serwer wskazując na ten plik, używając opcji --config lub -c:
json-server db.json -c json-server.jsonJeżeli plik konfiguracyjny będzie dokładnie nazywał się: json-server.json, to zostanie on automatycznie załadowany podczas uruchamiania serwera, więc można pominąć opcję --config lub -c. Można również posłużyć się komendami wiersza poleceń, jakie zapewnia JSON Server; wystarczy wpisać w konsoli: json-server -h lub json-server --help, aby poznać dostępne opcje. Na przykład, żeby zmienić port, wystarczy wpisać:
json-server db.json -p 3001Więcej informacji można znaleźć na stronie projektu.
Możliwości
JSON Server dostarcza wiele przydatnych funkcji na potrzeby mock API. Najważniejsze z nich to:
Wyszukiwanie pełnotekstowe
Aby umożliwić wyszukiwanie pełnotekstowe, do URI trzeba dodać opcjonalny parametr q:
GET /posts?q=jsonTo zapytanie zwróci wszystkie posty, w których w jakimkolwiek polu pojawi się słowo “json”; w naszym przypadku będą to dwa posty.
Filtry
Można stosować filtry do zapytań, używając znaku ?:
GET /posts?title=json-serverTo zapytanie zwróci wszystkie posty, w których tytuł to “json-server”; w naszym przypadku będzie to jeden post.
Można również połączyć kilka filtrów, dodając ampersand między różnymi filtrami:
GET /posts?title=jsonplaceholder&author=also+typicodeTo zapytanie zwróci wszystkie posty, których tytułem jest “jsonplaceholder”, a autor to “also typicode”; w naszym przypadku będzie to jeden post. Należy zauważyć, że nazwisko autora jest zakodowane.
Aby dostać się do bardziej zagłębionych propertiesów, należy użyć . (kropki):
GET /posts?author.firstname=firstnameTo zapytanie zwróci wszystkie posty, których imieniem autorem jest “firstname”; w naszym przypadku będzie to jeden post.
Operatory
JSON Server oferuje także operatory logiczne, niezbędne do dalszego odfiltrowywania wyników. Można użyć _gte i _lte, np.:
GET /posts?id_gte=10&id_lte=20otrzymując w odpowiedzi 11 postów od id=10 do id=20.
Można użyć _ne, by wyłączyć wartość:
GET /posts?id_ne=10w odpowiedzi otrzymamy 49 postów od id=1 do id=50, z pominięciem postu o id=10.
Użycie _like umożliwia przefiltrowanie po danym polu:
GET /posts?title_like=jsonw odpowiedzi otrzymamy dwa posty, w których w polu tytuł pojawiło się słowo “json”.
Parametr _like rozpoznaje również wyrażenia regularne (RegExp):
GET /posts?title_like=[\s]w odpowiedzi otrzymamy jeden post, w którym w polu tytuł znajduje się “ “ (spacja).
Stronicowanie
Domyślnie JSON Server umożliwia stronicowania z 10 elementami na stronie dzięki _page:
GET /posts?_page=2w naszym przypadku to zapytanie zwróci 10 postów, od postu o id=11 do postu o id=20.
Domyślną liczbę elementów można zmienić, używając parametru _limit:
GET /posts?_page=2&_limit=20w naszym przypadku to zapytanie zwróci 20 postów, od postu o id=21 do postu o id=40.
Wycinanie (slice)
Używając parametrów _start i _end lub _limit można otrzymać określony zakres elementów:
GET /posts?_start=20&_end=31
GET /posts?_start=20&_limit=11w naszym przypadku oba zapytanie zwrócą 11 postów, od postu o id=21 do postu o id=31.
Sortowanie
JSON Server pozwala również zażądać posortowanych danych z API. Należy użyć parametrów _sort i _order dla określenia właściwości, którą chcesz sortować i jej kolejności (domyślnie kolejność jest rosnąca). Jeśli sortowanie odbywa się na polu tekstowym, to elementy będą sortowane alfabetycznie.
GET /posts?_sort=title&_order=DESCW naszym przypadku to zapytanie zwróci wszystkie elementy posortowane malejącą względem tytułu.
Baza danych
Wykonując zapytanie:
GET /dbw odpowiedzi otrzymujemy całą aktualną bazę (snapshot):
{
"posts": [
{
"id": 1,
"title": "json-server",
"author": "typicode"
},
{
"id": 2,
"title": "jsonplaceholder",
"author": "also typicode"
},
{
"id": 3,
"title": "another post",
"author": {
"firstname": "firstname",
"lastname": "lastname"
}
}
],
"comments": [
{
"id": 1,
"body": "some comment",
"postId": 1
}
],
"profile": {
"name": "typicode"
}
}Można również wykonać zrzut aktualnej zawartości bazy (snapshot) poprzez konsolę, w której uruchomiliśmy serwer. W tym celu w konsoli należy wpisać s i nacisnąć Enter. W odpowiedzi w konsoli otrzymamy np.:
Saved snapshot to db-1485326956546.jsona na dysku zostanie utworzony plik db-1485326956546.json ze zrzutem bazy.
Homepage
GETSerwuje katalog ./public lub zwraca domyślny plik index (który też można zastąpić własnym):
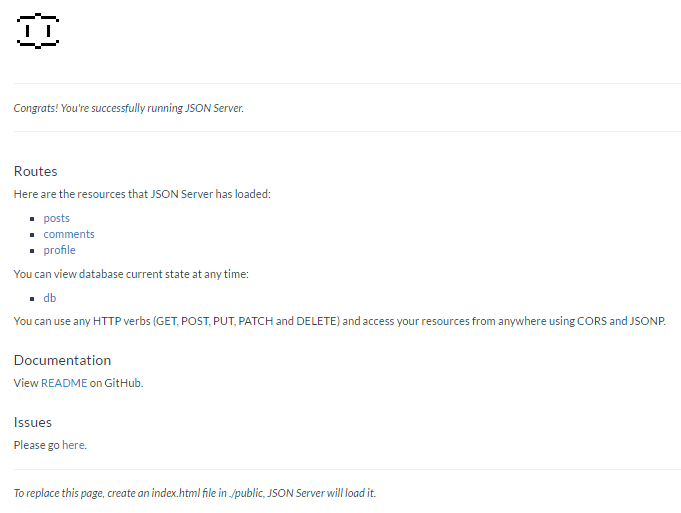
Źródła danych
Jak już wspomniałem wcześniej, istnieją trzy możliwe źródła danych. Jeżeli nie potrzebujemy wielu danych testowych, możemy utworzyć własny, nieskomplikowany plik jsonowy i użyć go jako źródło danych dla naszego serwera.
Jeżeli jednak chcemy dysponować większą liczbą danych testowych, a nie zależy nam dokładnie na tym, jakie one są, możemy wykorzystać gotowiec w postaci JSONPlaceholder. Jest to darmowy onlineowy serwis RESTowy wspierający testowanie i prototypowanie. Nieodzowny, kiedy chcemy wypróbować jakąś nową bibliotekę, stworzyć samouczek (tutorial) lub po prostu nauczyć się kolejnego narzędzia czy frameworka. Nie musimy się rejestrować ani niczego konfigurować JSONPlaceholder oferuje nam najczęściej wykorzystywane podstawowe API:
/posts- 100 elementów/comments- 500 elementów/albums- 100 elementów/photos- 5000 elementów/todos- 200 elementów/users- 10 elementów
Oferowane dane są relacyjne; np. posty mają id użytkownika, a komentarze - id postu. Dzięki czemu możemy budować zapytania zagnieżdżone:
GET /posts/1/commentsw naszym przypadku to zapytanie zwróci 5 komentarzy dla postu o id=1, co dokładnie odpowiada zapytaniu:
GET /comments?postId=1Tak jak w przypadku każdego innego źródła danych, możemy wykonywać wszystkie podstawowe żądania: GET, POST, PUT, PATCH, DELETE i OPTIONS.
Aby nie musieć za każdym razem łączyć się ze zdalnym schematem (http://jsonplaceholder.typicode.com/db), można przechwycić całą bazę i zapisać ją do pliku jsonowego poprzez wprowadzenie s + Enter w konsoli, a następnie użyć takiego schematu jako nowego źródła danych.
Jeżeli jednak potrzebujemy większej ilości customowych danych testowych, należy je sobie odpowiednio wygenerować.
Generowanie danych
Jak dotąd dane wprowadzane były ręcznie lub brane ze zdalnego schematu, co działa dobrze dla większości zastosowań. Jednak, gdy trzeba będzie stworzyć bazę z większą ilością realistycznych danych, które pasują do naszego projektu, trzeba posłużyć się dodatkowymi narzędziami.
Faker.js
Pozwala na generowanie dużych ilości różnego rodzaju testowych danych i dobrze współpracuje z JSON Server.
Aby zainstalować moduł, otwórz konsolę i wpisz polecenie:
npm install fakerTeraz za pomocą faker.js możemy stworzyć skrypt do generowania 50 postów dla naszej aplikacji. Należy utworzyć plik JavaScript o nazwie users.js, który eksportuje funkcję do generowania danych:
function generateUser () {
var faker = require('faker');
// Change of localization, the default language locale is set to English
faker.locale = "pl";
var db = { "users": [] };
for (var id = 0; id < 10; id++) {
var firstName = faker.name.firstName();
var lastName = faker.name.lastName();
var avatar = faker.image.avatar();
var iq = faker.random.number({min:70, max:160});
var profile = faker.random.arrayElement(['admin', 'user', 'tester', 'moderator']);
var phoneNumber = faker.phone.phoneNumberFormat();
var email = faker.internet.email();
var city = faker.address.city();
var street = faker.address.streetPrefix() + ' ' + faker.address.streetName() + ' ' + faker.random.number({min:1, max:500});
var motto = faker.lorem.sentence();
var account = faker.finance.account();
var companyName = faker.company.companyName();
var registrationDate = faker.date.past();
db.users.push({
"id": id,
"first_name": firstName,
"last_name": lastName,
"avatar": avatar,
"iq": iq,
"profile": profile,
"phone": phoneNumber,
"email": email,
"city": city,
"street": street,
"motto": motto,
"account": account,
"company_name": companyName,
"registration_date": registrationDate
});
}
return db;
}
module.exports = generateUser;Używając dodatkowo biblioteki lodash, możemy sobie uprościć nasz generator:
module.exports = function() {
var faker = require('faker');
var _ = require('lodash');
return {
"users": _.times(10, function(n) {
var firstName = faker.name.firstName();
var lastName = faker.name.lastName();
var phoneNumber = faker.phone.phoneNumberFormat();
return {
"id": n,
"first_name": firstName,
"last_name": lastName,
"phone": phoneNumber
// ...
}
})
};
};Teraz możemy powiedzieć JSON Server, aby korzystał z tego generatora jako źródła danych:
json-server users.jsteraz wchodząc na http://localhost:3000/users, powinniśmy zobaczyć obiekt JSON z 10 fałszywymi użytkownikami, zawierającymi realistyczne dane, gotowe do natychmiastowego użycia, np.:
{
"id": 1,
"first_name": "Henryka",
"last_name": "Piórkowski",
"avatar": "https://s3.amazonaws.com/uifaces/faces/twitter/vikashpathak18/128.jpg",
"iq": 78,
"profile": "moderator",
"phone": "12-017-03-71",
"email": "Walenty.Muszyski@hotmail.com",
"city": "North Maurycy",
"street": "al. Wojtczak Hills 176",
"motto": "Sit rerum sunt nobis consectetur accusamus dolorem nisi architecto.",
"account": "46051528",
"company_name": "Wojtczak, Jurkiewicz and Wojtasik",
"registration_date": "2016-09-20T21:58:51.480Z"
}Zamiast ciągle na nowo generować dane, można wyeksportować raz wygenerowane dane do pliku json. W tym celu trzeba lekko zmodyfikować plik users.js:
function generateUser () {
var faker = require('faker');
var db = { "users": [] };
for (var id = 0; id < 10; id++) {
var firstName = faker.name.firstName();
var lastName = faker.name.lastName();
var phoneNumber = faker.phone.phoneNumberFormat();
db.users.push({
"id": id,
"first_name": firstName,
"last_name": lastName,
"phone": phoneNumber
// ...
});
}
return db;
}
console.log(JSON.stringify(generateUser()));a następnie uruchomić następujące polecenie w konsoli:
node users.js > users.jsonTaki plik możemy użyć jako nowe źródło danych.
Faker.js może generować ogromną ilość różnego typu fałszywych danych, oprócz prostych nazw i numerów, warto więc przejrzeć jego API, aby zobaczyć, które dane odpowiadają potrzebom naszej aplikacji.
Casual
Oferuje podobną funkcjonalność co faker.js. Aby zainstalować moduł, otwórz konsolę i wpisz polecenie:
npm install casualNasz wcześniejszy przykład dla casual wyglądałby tak:
function generateUser () {
// Default locale is en_US; there is no pl locale
var casual = require('casual').de_DE;
var db = { "users": [] };
for (var id = 0; id < 10; id++) {
var firstName = casual.first_name;
var lastName = casual.last_name;
var avatar = '';
var iq = casual.integer(from = 70, to = 160);
var profile = casual.random_element(['admin', 'user', 'tester', 'moderator']);
var phoneNumber = casual.phone;
var email = casual.email;
var city = casual.city;
var street = 'ul. ' + casual.street + ' ' + casual.building_number;
var motto = casual.sentence;
var account = casual.card_number();
var companyName = casual.company_name;
var registrationDate = casual.date();
db.users.push({
"id": id,
"first_name": firstName,
"last_name": lastName,
"avatar": avatar,
"iq": iq,
"profile": profile,
"phone": phoneNumber,
"email": email,
"city": city,
"street": street,
"motto": motto,
"account": account,
"company_name": companyName,
"registration_date": registrationDate
});
}
return db;
}
module.exports = generateUser;Przykładowy wygenerowany użytkownik wygada tak:
{
"id": 1,
"first_name": "Waltraud",
"last_name": "Jäger",
"avatar": "",
"iq": 127,
"profile": "admin",
"phone": "01887 / 5854912",
"email": "Weiß_Björn@yahoo.com",
"city": "Unter Freilitz",
"street": "ul. Am Brückenpark 77a",
"motto": "Mollitia cupiditate soluta perspiciatis error.",
"account": "5250506264455321",
"company_name": "Winkler GmbH",
"registration_date": "22.01.2012"
}Casual również może generować dużą ilość różnego typu testowych danych, warto więc przejrzeć jego API, aby zobaczyć, które dane odpowiadają potrzebom twojej aplikacji.
Używanie API obu bibliotek w jest dość intuicyjne. Jak widać, większość funkcjonalności w casual i faker.js pokrywa się, natomiast niektóre się uzupełniają. Faker.js ma bardziej przejrzyste API. Jednak nic nie stoi na przeszkodzie, aby wykorzystać obie biblioteki naraz i jednocześnie korzystać z ich dobrodziejstw.
Podsumowanie
Teraz powinieneś być w stanie szybko i łatwo stworzyć własne mock API i dodać do niego potrzebne dane testowe. Jak widać, postawienie w pełni funkcjonalnego testowego REST API nie zajmuje dużo czasu, dzięki JSON Server i użytecznym generatorom danych, takim jak Faker.js i Casual. Te narzędzia mogą stać się nieodzowne w twojej pracy na frontendzie. Możesz zacząć pracę nad aplikacją bez czekania aż powstanie w miarę funkcjonalny, stabilny backend i szybciej przetestujesz nowe pomysły (prototypowanie). Będziesz mógł się zapoznać z nowymi narzędziami czy bibliotekami, a na dodatek nie musisz być online. Łatwiej porównasz również różne frameworki, dysponując spójnym i jednolitym restowym API.
Do pracy nad artykułem wykorzystano biblioteki i narzędzia w następujących wersjach:
- Node.js: 6.9.4 LTS
- Chrome: 55
- json-server: 0.9.4
- jsonplaceholder: 0.3.3
- faker.js: 3.1.0
- casual: 1.5.8
Autor: Łukasz Santarek

Programista, konsultant IT. Z wykształcenia elektronik, z zamiłowania informatyk. Interesuje się językami programowania, bazami danych oraz technikami i strategiami tworzenia oprogramowania. W pracy zajmuje się głównie Javą, a ostatnio również odnajduje się w tworzeniu aplikacji webowych, opartych głównie na Angularze. W wolnym czasie czyta beletrystykę i książki popularnonaukowe. Czasem można go spotkać w teatrze lub na leśnych szlakach.